序列化页面线格式¶
Presto 使用序列化页面二进制列式格式在阶段之间交换数据。
数据可以被压缩、加密并包含校验和。布局是一个标题,后面跟着若干列,然后是各个列。

标题¶
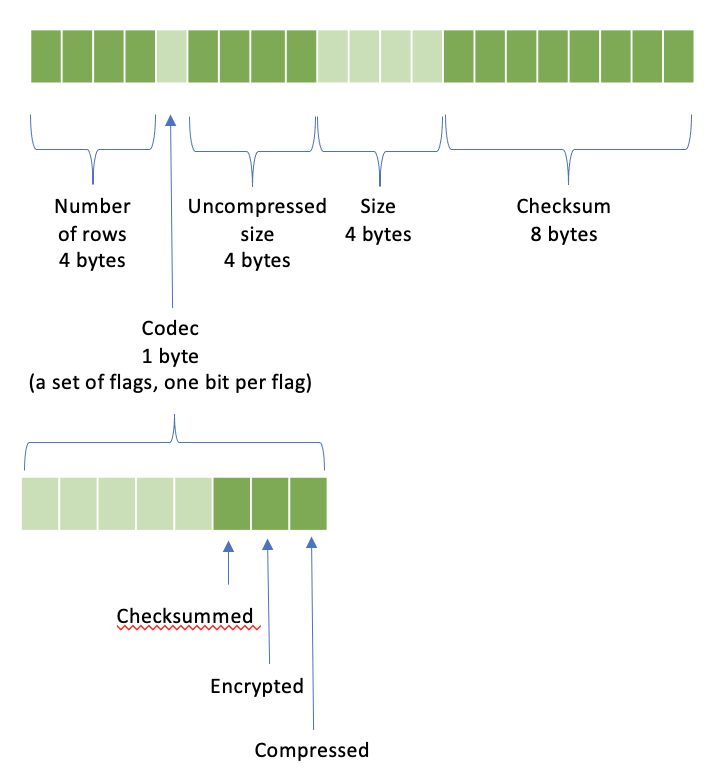
标题包含以下内容:
字段 |
大小 |
|---|---|
行数 |
4 字节 |
编解码器 |
1 字节 |
未压缩大小 |
4 字节 |
大小 |
4 字节 |
校验和 |
8 字节 |
编解码器是一组标志,每个标志占一个位。* 第一位设置,表示数据被压缩 * 第二位设置,表示数据被加密 * 第三位设置,表示包含校验和
大小是指标题之后有效载荷的大小。如果数据未压缩,大小和未压缩大小相同。如果数据被压缩,大小是指压缩数据的尺寸,而未压缩大小是指压缩前数据的尺寸。
校验和是在以下字节上计算的 CRC32,按照指定顺序:* 标题之后的数据 * 编解码器(1 字节) * 行数(4 字节) * 未压缩大小(4 字节) 如果编解码器没有设置校验和位,校验和必须为零。
注意:列数不是标题的一部分。它存储在标题之后 4 字节的位置。
列¶
每列都以一个标题开头。数据紧随其后。
列标题¶
列标题指定列的编码方式。
编码名称的长度 - 4 字节
编码名称
Presto 类型支持的编码和映射如下:
编码名称 |
Presto 类型 |
|---|---|
BYTE_ARRAY |
BOOLEAN, TINYINT, UNKNOWN |
SHORT_ARRAY |
SMALLINT |
INT_ARRAY |
INTEGER, REAL |
LONG_ARRAY |
BIGINT, DOUBLE, TIMESTAMP |
INT128_ARRAY |
未使用 |
VARIABLE_WIDTH |
VARCHAR, VARBINARY |
ARRAY |
ARRAY |
MAP |
MAP |
MAP_ELEMENT |
n/a |
ROW |
ROW |
DICTIONARY |
n/a |
RLE |
n/a |
参见 presto-common/src/main/java/com/facebook/presto/common/block/BlockEncodingManager.java
例如,INTEGER 列的标题描述 INT_ARRAY 编码。编码名称的长度为 9,因此前 4 个字节将为 0 0 0 9。接下来的 9 个字节存储 INT_ARRAY 字符串。

空标志¶
所有列都包含 1 字节的 has-nulls 标志。0 表示没有空值。1 表示可能包含空值。如果 has-nulls 字节为 1,则使用 1 位表示每个标志的单独空标志。0 表示该值非空。1 表示该值为 null。
Has-nulls 标志 - 1 字节
[可选] 空标志 - 行数 / 8 字节;每个标志 1 位;位按字节逆序存储;每个字节的第一个标志是最高位。
假设我们有 10 行,空值出现在从零开始的第 1、4、6、7、9 行。空标志将用 3 个字节表示。第一个字节存储 has-null 标志:1。第二个字节存储前 8 行的空标志。第三个字节存储最后 2 行的空标志。

XXX_ARRAY 编码¶
BYTE_ARRAY、INT_ARRAY、SHORT_ARRAY、LONG_ARRAY 和 INT128_ARRAY 编码的区别仅在于每个值使用的字节数。
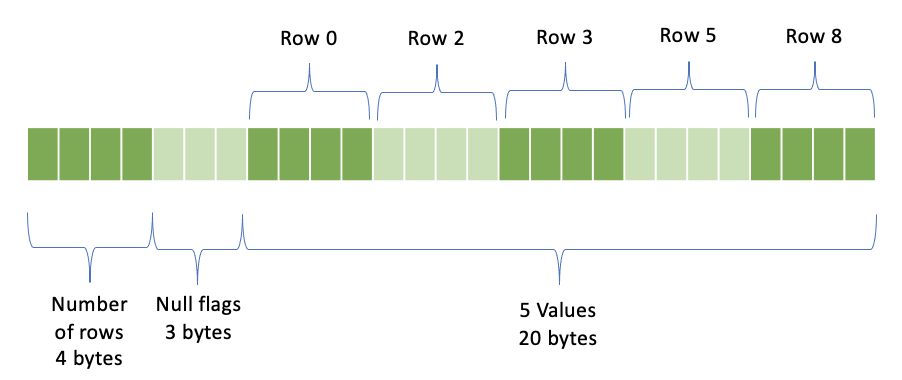
数据布局如下:
行数 - 4 字节
空标志
值 - (行数 - 空值数量) * <每个值的字节数> 字节;仅表示非空值的行
每个值的字节数为:
编码名称 |
每个值的字节数 |
|---|---|
BYTE_ARRAY |
1 |
SHORT_ARRAY |
2 |
INT_ARRAY |
4 |
LONG_ARRAY |
8 |
INT128_ARRAY |
16 |
以空标志部分的示例为例,假设我们有一个包含 10 行的整数列,空值出现在从零开始的第 1、4、6、7、9 行。我们将有 4 个字节存储行数:10,后面跟着 3 个字节的空标志,再后面跟着 20 个字节,代表第 0、2、3、5、8 行的 5 个非空整数的值。
VARIABLE_WIDTH 编码¶
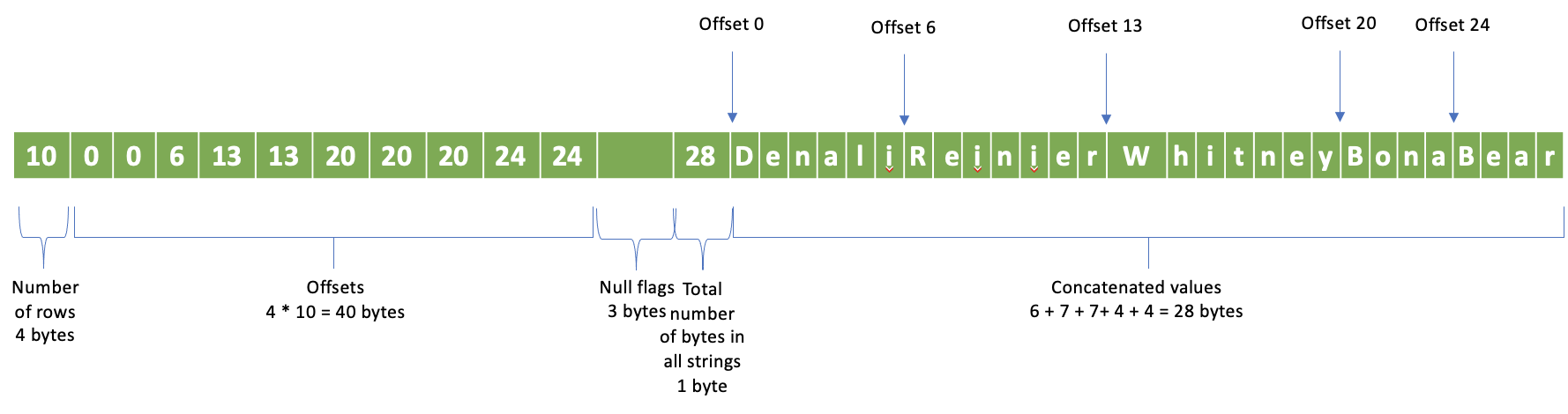
行数 - 4 字节
偏移量 - 行数 * 4 字节;每个偏移量 4 字节
空标志
所有值中的总字节数 - 4 字节
连接的值
再次以空标志部分的示例为例,假设我们有一个包含 10 行的字符串列,空值出现在从零开始的第 1、4、6、7、9 行。非空行将具有以下值:0 - Denali、2 - Reinier、3 - Whitney、5 - Bona、8 - Bear。我们将有 4 个字节存储行数:10,后面跟着 40 个字节的偏移量,再后面跟着 3 个字节的空标志,接着是 1 个字节存储所有字符串的总大小:28,最后是连接的字符串值。请注意,我们为所有行都设置了偏移量,而不仅仅是非空行。
ARRAY 编码¶
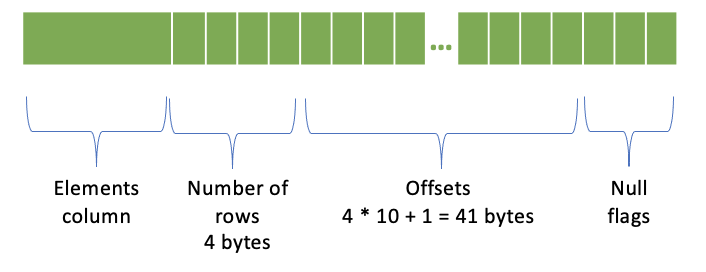
元素列
行数 - 4 字节
偏移量 - (行数 + 1) * 4 字节;每个偏移量 4 字节
空标志
包含 10 行的数组列的表示方式如下:
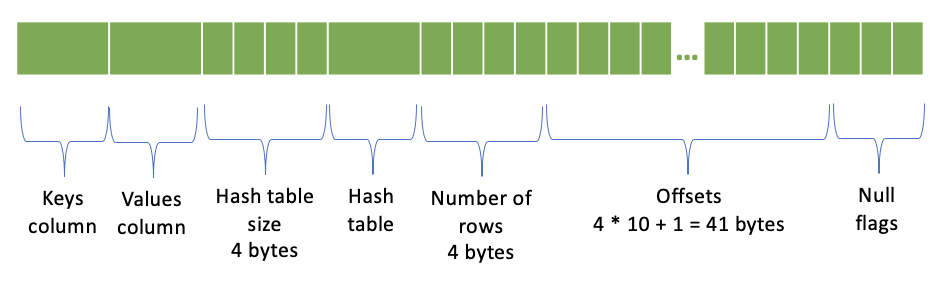
MAP 编码¶
键列
值列
哈希表大小(哈希表中 4 字节块的数量) - 4 字节
[可选] 哈希表:<哈希表大小> * <4 字节>
行数 - 4 字节
偏移量 - (行数 + 1) * 4 字节;每个偏移量 4 字节
空标志
包含 10 行的映射列的表示方式如下:
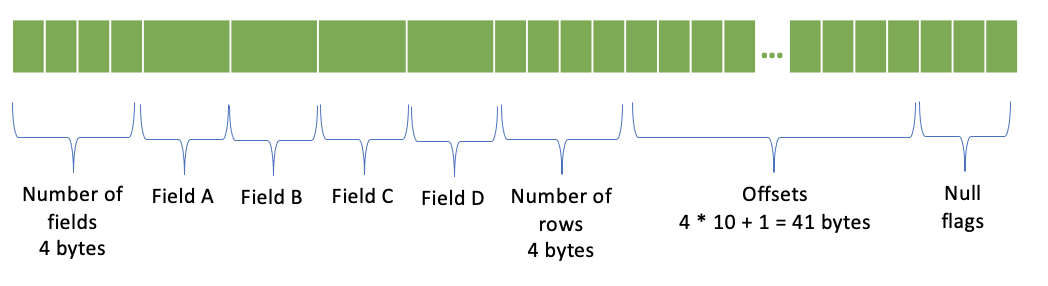
ROW 编码¶
字段数量 - 4 字节
每个字段对应一列
行数 - 4 字节
偏移量 - (行数 + 1) * 4 字节;每个偏移量 4 字节
空标志
仅针对非空行序列化嵌套列。在存在空行的情况下,嵌套列的行号与顶层行号不匹配。偏移量指定嵌套列的行号。
再次以空标志部分的示例为例,假设我们有一个类型为 ROW(a, b, c, d) 的列,包含 10 行,空值出现在从零开始的第 1、4、6、7、9 行。嵌套列将只有 5 行,偏移量为:0、0、1、2、0、3、0、0、4、0。空行的偏移量为零。
注意:偏移量是冗余信息,因为可以根据空标志重建偏移量。
字典编码¶
行数 - 4 字节
字典值列。该列本身是一个序列化块,其编码可以是本文档中提到的任何编码。
索引 - 行数 * 4 字节;每个索引 4 字节
字典 ID - 24 字节
RLE 编码¶
行数 - 4 字节
单行常量值列
其他用法¶
序列化页面格式也用于在协调器发送给工作节点的计划片段中指定常量值。在这种情况下,二进制表示将使用 base64 编码转换为 ASCII 字符串。
例如,SELECT array[1, 23, 456] 查询的计划包含一个 Project 节点,其中 array[1, 23, 456] 值表示为序列化页面格式的二进制 base64 编码。
- Project[projectLocality = LOCAL] => [expr:array(integer)]
Estimates: {rows: 1 (51B), cpu: 51.00, memory: 0.00, network: 0.00}
expr := [Block: position count: 3; size: 92 bytes]
此外,当会话属性 exchange_materialization_strategy 为 ALL 且 temporary_table_storage_format 为 PAGEFILE 时,此格式用于存储中间数据。