交换物化¶
Presto 允许交换物化来支持内存密集型查询。此机制将 MapReduce 样式的执行引入 Presto 的 MPP 架构运行时,并且可以与 溢出到磁盘 一起使用。
介绍¶
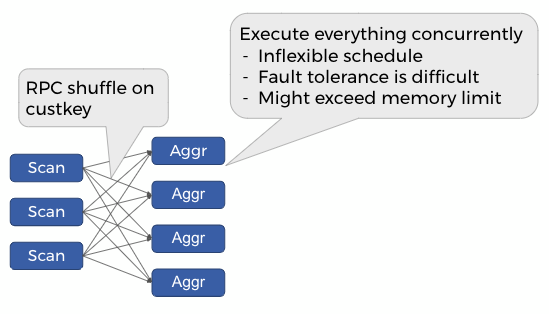
与其他 MPP 数据库一样,Presto 利用 RPC shuffle 来实现对联接和聚合的有效且低延迟的查询执行。但是,RPC shuffle 还要求所有生产者和消费者同时执行,直到查询完成。
为了说明这一点,请考虑以下聚合查询
SELECT custkey, SUM(totalprice)
FROM orders
GROUP BY custkey
下图展示了此查询在 Presto 经典模式下的执行方式
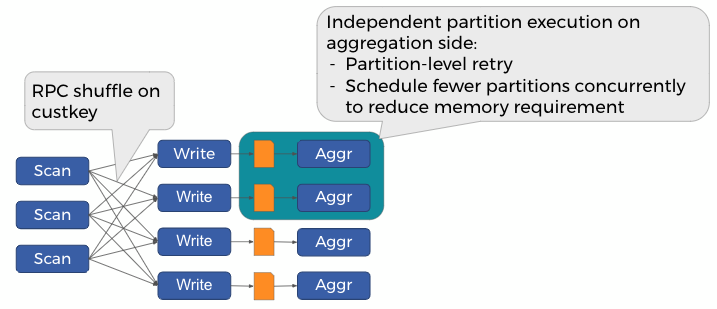
使用交换物化,中间 shuffle 数据被写入磁盘(目前,它始终是临时 Hive 存储桶表)。这为聚合端的灵活调度策略提供了机会,因为一次只需要在内存中保存一部分聚合数据 - 这种执行策略在 Presto 中称为“分组执行”。
使用交换物化¶
可以通过设置以下 3 个会话属性在每个查询的基础上启用交换物化:exchange_materialization_strategy、partitioning_provider_catalog 和 hash_partition_count
SET SESSION exchange_materialization_strategy='ALL';
-- Set partitioning_provider_catalog to the Hive connector catalog
SET SESSION partitioning_provider_catalog='hive';
-- We recommend setting hash_partition_count to be at least 5X-10X about the cluster size
-- when exchange materialization is enabled.
SET SESSION hash_partition_count = 4096;
为了使用户能够轻松地使用交换物化,管理员可以利用 会话属性管理器 根据客户端标签自动设置会话属性。中的示例 会话属性管理器 演示了如何为带有 high_mem_etl 标签的查询自动启用交换物化。